Automatic Cloudfront invalidation with Amazon Lambda

Serverless. That is the new magic word. Forget about containers, virtualization, operating systems, patching, scaling... Just write the code and upload it to Amazon Lambda.
What is that?
Let's copy and paste:
AWS Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume - there is no charge when your code is not running. With Lambda, you can run code for virtually any type of application or backend service - all with zero administration. Just upload your code and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app.
Basically, you create Lambda Functions with your own code (Python, JS, Java, C#). Those functions can be associated to a particular AWS service and when something happens they trigger and run the code. For example, a user uploads an image to the forum. With Lambda Functions you could:
- Automatically check for nudity when the image is put on S3 by using Amazon Rekognition.
- Send an alarm Slack in case the image contains nudity.
- If the filter pass, then create a thumbnail.
- Invalidate Cloudfront caches of that forum post.
And everything could be triggered by a simple "put" command in one of the configured S3 buckets. Nice!
Actually, you could build your entire app with Amazon Lambda Functions without having to start a single server.
Show me an example
I have my entire site and blog hosted in Amazon S3, then distributed around the world with Amazon Cloudfront. I have the caches configured with a really large expiration time, so everytime I update a html file I need to create an invalidation.
It is a pain to have to login and do it manually for every single update, so I am going to create a Lambda Function that does that for me. Here is the step by step:
1- Login to Amazon Lamda
Well, easy, just need to login on your Amazon Console, choose the Availability Region and then open the AWS Service. The first time it you will show the usual splash screen, just click on "Get Started Now":

2- Create our function
Since there are no user-defined functions, it will show a list of blueprints that can be used as a template to create our own. In this case, I am going to choose Blank Function.
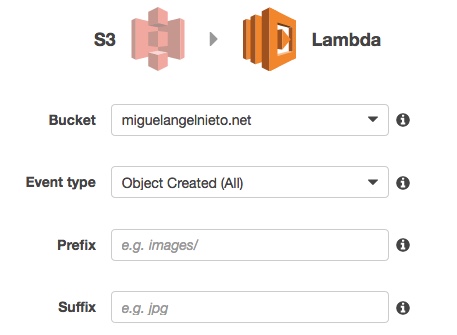
It will start the wizard. I need to choose which Amazon service will trigger the function. In this case, when a new object is copied (or updated) on my "miguelangelnieto.net" bucket, the code will be triggered.
Then click next. In the next section I give a name to the function and write the code. My function will be called "CacheInvalidationOnWebPageUpdate" and the code will be in python 2.7:
from __future__ import print_function
import boto3
import time
def lambda_handler(event, context):
path = []
for items in event["Records"]:
if items["s3"]["object"]["key"] == "index.html":
path.append("/")
else:
path.append("/" + items["s3"]["object"]["key"])
print(path)
client = boto3.client('cloudfront')
invalidation = client.create_invalidation(DistributionId='E8F6HK73EP0LT',
InvalidationBatch={
'Paths': {
'Quantity': 1,
'Items': path
},
'CallerReference': str(time.time())
})
The lambda_handler receives the event from S3. From that event I store the changed object path in "path" list. After that I create a cache invalidation in my Cloudfront Distribution for that object.
There is a small hack there. If the file is index.html, then the path to invalidate is "/".
Yes, this method has a flaw. It makes no sense to invalidate an object that never existed before. But since invalidation calls are so cheap (free for me because of the small number of request I make) I don't really care :D
2- Create the role
This Lambda function needs to be able to create the invalidation requests in Cloudfront, so a role that allows that task needs to be applied to it. In my example I called it " lambda_cloudfront_invalidation_execution". Yep, pretty long but explanatory one.

This is the role code:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"cloudfront:CreateInvalidation"
],
"Resource": [
"*"
]
}
]
}
It basically gives the lambda function the permission to create logs on each execution and add the invalidations to CloudFront.
The next step is just to enable the trigger and create the function. By default Amazon will assign 128MB to it. More about this later on.
Test
So, let's upload an updated index.html to my website:
$ aws s3 sync ./ s3://miguelangelnieto.net --exclude "*.DS_Store*"
upload: ./index.html to s3://miguelangelnieto.net/index.html
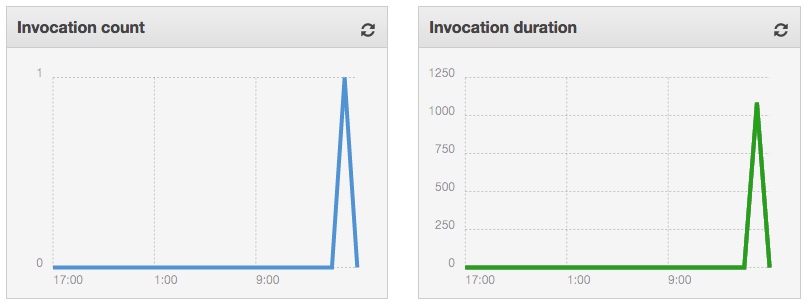
CLoudWatch graphs will show one invocation of the function:
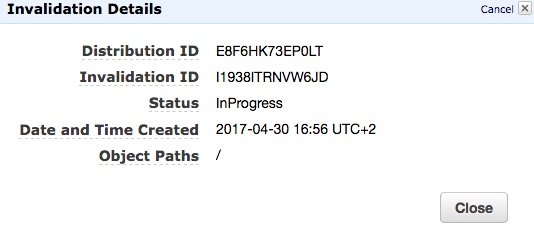
And CloudFront will be already executing the invalidation task for our object to remove it from the cache of the CDN:
Cloudwatch shows the log of the invocation:
START RequestId: 234d7ad9-2db5-11e7-96c6-a5828501763c Version: $LATEST
['/']
END RequestId: 234d7ad9-2db5-11e7-96c6-a5828501763c
REPORT RequestId: 234d7ad9-2db5-11e7-96c6-a5828501763c Duration: 1085.21 ms Billed Duration: 1100 ms Memory Size: 128 MB Max Memory Used: 36 MB
Costs
Why the memory parameter is important? Basically depending on the memory reserved for the invocation we will have a different number of free calls per month. With 128MB I can call this function 3.200.000 times per month for free. After that, the cost will be 0.000000208$ for every 100ms of execution.
As shown in the previous log, my function only needed 36MB and 1 second to run. So, I can call it more than 3 million times and still pay nothing at the end of the month.